

Dzisiejszy temat troszkę przeskoczył do góry na liście tematów do opisania, ale niejako sam wywołałem go do tablicy stawiając nowy serwer do obsługi m.in. kopii zapasowych innych serwerów/stron internetowych.
Spis treści w artykule
Simple Storage Service (S3)
Nie będę zbytnio wdawał się w szczegóły co to jest S3 – zainteresowani albo wiedzą, albo znajda takie informacje na stronach dostawców tego typu usług, a reszcie wystarczy pewnie informacja, że jest to jakby internetowy dysk (object storage), który możemy wykorzystać do przechowywania naszych plików.
Zarazem jest to na tyle uniwersalna technologia/usługa, że możemy taką dodatkową przestrzeń traktować zarówno jako miejsce na kopie zapasowe np. serwera czy strony internetowej, ale również jako normalną przestrzeń, w której możemy trzymać np. większe pliki multimedialne naszej strony (mam w planach kilka wpisów na ten temat, więc pewnie za jakiś czas…).
Dużym atutem usług S3 jest również to, że niezależnie od dostawy usługi zazwyczaj są one ze sobą zgodne, co umożliwia relatywnie swobodne przenoszenie zasobów między rożnymi dostawcami/usługami.
Korzystanie z Simple Storage Service (S3) w systemie Linux (Debian/Raspbian)
Wprawdzie chyba najpopularniejszych (i zarazem prekursorem tego typu usługi) jest Amazon, to ja na potrzeby naszego poradnika skorzystam z usługi „pliki w chmurze” oferowanej przez e24cloud.com/Beyond.pl – ale Wy możecie skorzystać z dowolnej innej usługi zgodnej ze standardem S3.
s3fs (s3fs-fuse)
Wprawdzie programów z których można skorzystać jest co najmniej kilka, to ja najczęściej korzystam z s3fs, który jest prosty w konfiguracji, a zarazem działa bez (większych) problemów.
W tym poradniku będę opierał się na właśnie przeprowadzonej instalacji i konfiguracji w systemie Raspbian (Debian 8 Jessie), działającym na Raspberry Pi B (świeża instalka).
Instalacja s3fs-fuse w systemie Debian/Raspbian
Niestety s3fs nie znajdziemy (na razie?) w standardowych repozytoriach Debiana, dlatego musimy program pobrać i skompilować samodzielnie.
Zaczynamy od instalacji niezbędnych pakietów:
sudo apt-get install automake autotools-dev g++ git libcurl4-gnutls-dev fuse fuse-utils libfuse-dev libssl-dev libxml2-dev make pkg-configW razie błędu związanego z fuse-utils i przerwanej instalacji pakietów pozbywamy się go z listy:
sudo apt-get install automake autotools-dev g++ git libcurl4-gnutls-dev fuse libfuse-dev libssl-dev libxml2-dev make pkg-configNastępnie pobieramy, kompilujemy i instalujemy s3fs:
sudo git clone https://github.com/s3fs-fuse/s3fs-fuse.git
cd s3fs-fuse
sudo ./autogen.sh
sudo ./configure
sudo make
sudo make installCała operacja w przypadku Raspberry Pi trwa kilka(naście) minut.
Konfiguracja konta S3
Po instalacji musimy jeszcze skonfigurować program – w tym celu będziemy potrzebować:
- Adres serwera/usługi (będzie wymagane w dalszych krokach)
- Klucz API (coś w rodzaju nazwy użytkownika)
- Sekretny klucz API (coś w rodzaju hasła)
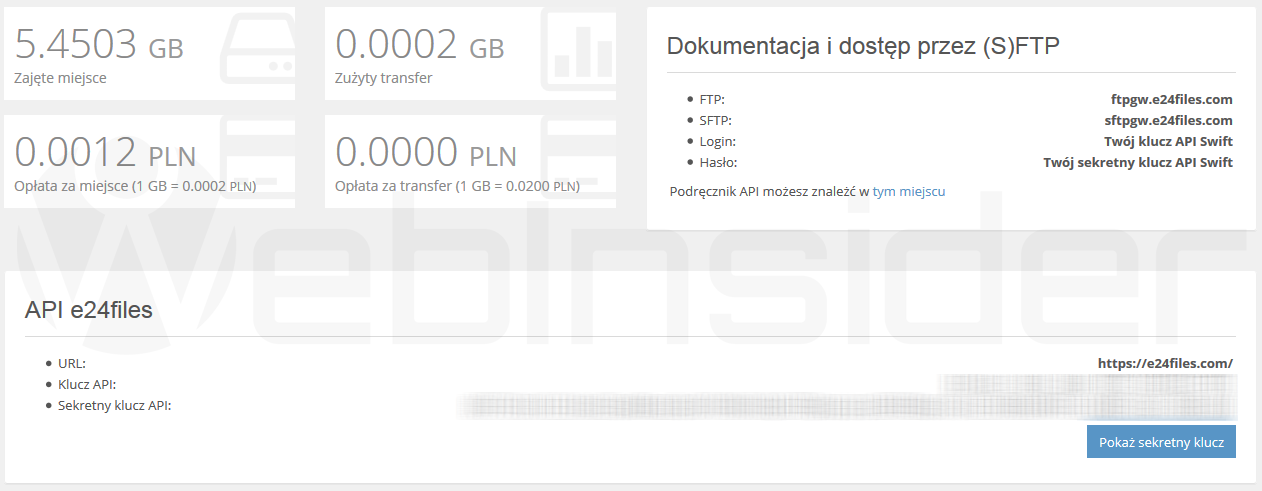
Plik z kluczami API
Gdy mamy niezbędne informacje (klucze API) tworzymy plik z danymi autoryzacyjnymi:
sudo nano /etc/passwd-s3fsW pliku tym zapisujemy klucz API i sekretny klucz API wg wzoru:
KluczAPI:SekretnyKluczAPIGdy korzystamy z więcej niż jednego kontenera (o tym za chwilę) podajemy również nazwę kontenera:
NazwaKontenera:KluczAPI:SekretnyKluczAPIKażda grupa (kontener + klucze API) w oddzielnej linii.
Ze względów bezpieczeństwa program nie zadziała, jeśli nie nadamy jeszcze odpowiednich uprawnień dla pliku z kluczami:
sudo chmod 600 /etc/passwd-s3fsI to właściwie cała (podstawowa) konfiguracja – zapowiadałem, że jest szybko i (relatywnie) prosto…
Tworzenie kontenera S3 (S3 bucket)
Zanim zamontujemy naszą pamięć zdalną jako element systemu plików musimy utworzyć jeszcze kontener (powiedzmy, że konto S3 to coś na wzór dysku fizycznego, a kontener to partycja na tym dysku), w którym będziemy trzymać pliki.
Kontener możecie utworzyć bezpośrednio z panelu zarządzania – jeśli jest dostępna taka opcja:
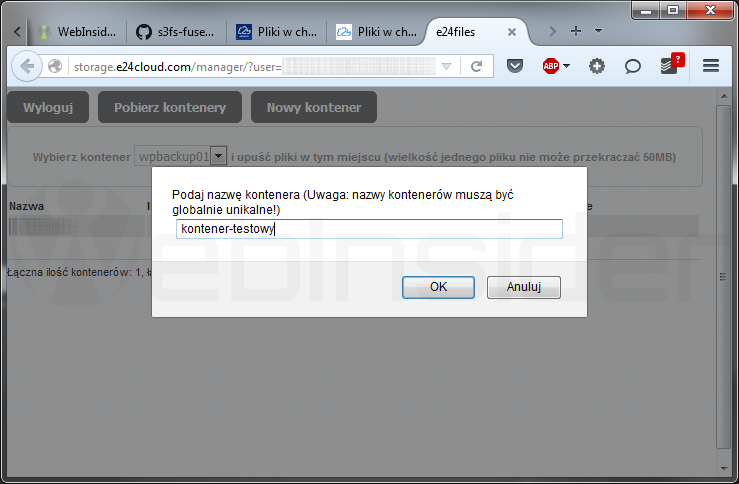
DragonDisk
Jeśli nie macie takiej opcji w Waszym panelu zarządzania lub w przypadku gdy chcecie uzyskać dostęp do pamięci również np. z systemu Windows i/lub planujecie więcej operacji warto skorzystać z dedykowanego do takich czynności programu, np. bezpłatnego DragonDisk:
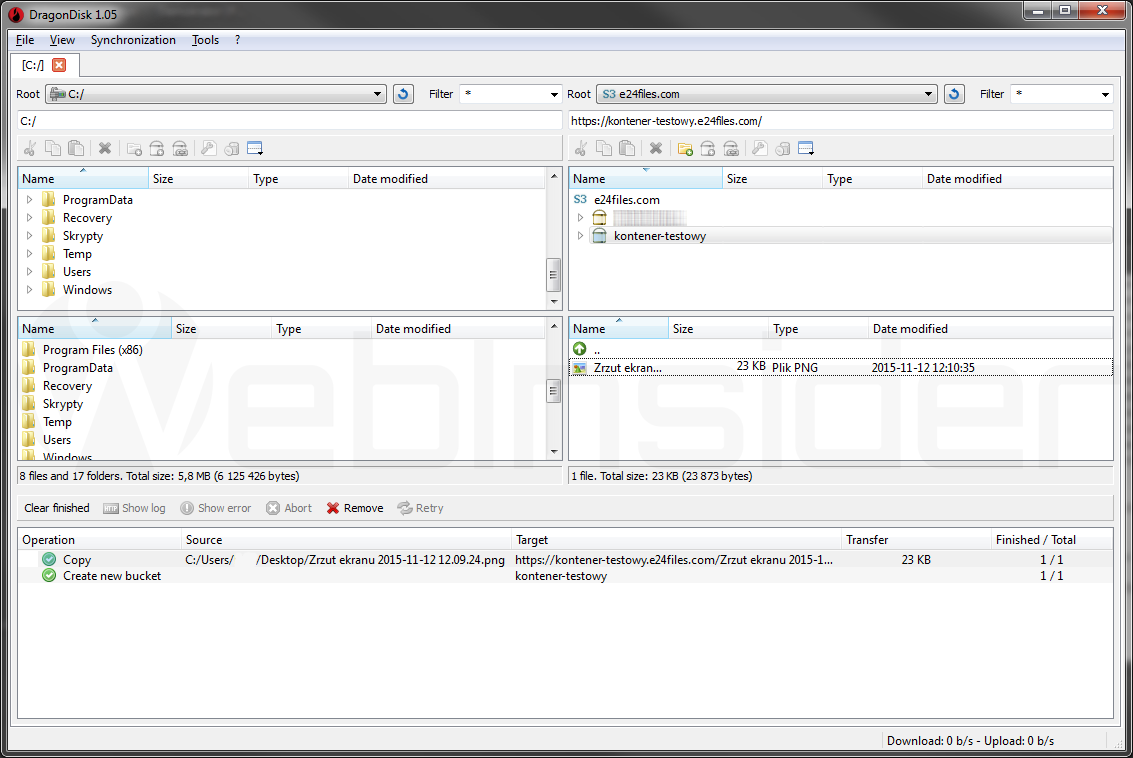
Jego obsługa nie powinna raczej sprawić problemów, a sam wygląd – jak widać – jest standardowy dla tego typu programów (okno podzielone na 2 części).
Tutaj macie przykładową konfigurację dla usługi „pliki w chmurze” (e24cloud):
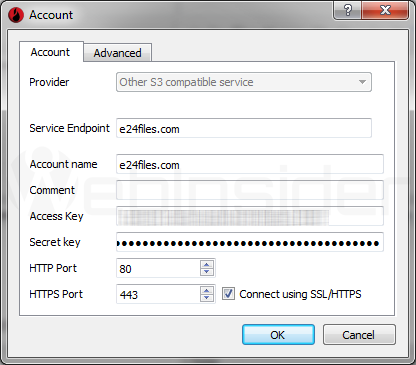
- Provider: Other S3 compatible service
- Service Endpoint: e24files.com
- Account name: e24files.com
- Access Key: Klucz API
- Secret Key: Sekretny klucz API
- HTTP Port: 80
- HTTPS Port: 433
- Connect using SSL/HTTPS
Montowanie kontenerów S3
Jeśli chodzi o podstawy związane z montowaniem dysków/zasobów w systemie Linux (Debian) zapraszam Was do tego wpisu – tutaj skupię się już tylko na elementach specyficznych dla usługi S3 i aplikacji s3fs:
sudo s3fs kontener /lokalny/punkt/montowania -o url="https://e24files.com" -o allow_otherJeśli występuje problem przy połączeniu z adresem po „https” (np. w Raspbien/Debian Wheezy bywały z tym problemy), i musimy skorzystać z „http”:
sudo s3fs kontener /lokalny/punkt/montowania -o url="http://e24files.com" -o allow_otherChoć ja zazwyczaj korzystam z polecenia ze wskazaniem pliku w którym znajdują się dane autoryzacyjne:
sudo s3fs kontener /lokalny/punkt/montowania -o url="https://e24files.com" -o passwd_file=/ścieżka/do/pliku/autoryzacyjnego -o allow_otherW naszym przypadku będzie to:
sudo s3fs kontener /lokalny/punkt/montowania -o url="https://e24files.com" -o passwd_file=/etc/passwd-s3fs -o allow_otherWprawdzie gdy korzystamy z pliku „/etc/passwd-s3fs” podawanie ścieżki do niego w tym poleceniu nie jest wymagane, to ja na wszelki wypadek (wyrabianie nawyków) i tak podaje.
Gdy coś nie działa
Może się zdarzyć, że podczas próby zamontowania zasobu S3 dostaniecie np. taki komunikat błędu:
ransport endpoint is not connectedWtedy warto dodać następujące parametry do polecenia:
-f -dCo da nam np. takie polecenie:
sudo s3fs kontener /lokalny/punkt/montowania -o url="https://e24files.com" -o passwd_file=/ścieżka/do/pliku/autoryzacyjnego -o allow_other -f -dOdmontowanie zasobu
Skoro jesteśmy przy montowaniu, to warto choćby wspomnieć jak odmontować taki zasób z lokalnego systemu plików.
Wprawdzie możemy skorzystać ze standardowego polecenia:
sudo umount /lokalny/punkt/montowaniaTo chyba bezpieczniej jest skorzystać z takiego polecenia:
sudo fusermount -u /lokalny/punkt/montowaniaMontowanie za pomocą fstab
Kontener możemy również zamontować podczas startu systemu, korzystając z pliku „fstab”:
sudo nano /etc/fstabW którym dodajemy linijkę wg wzoru:
s3fs#kontener /lokalny/punkt/montowania fuse allow_other,url=https://e24files.com 0 0W przypadku korzystania z tej metody (fstab) ścieżka i nazwa pliku autoryzacyjnego musi być taka jak podałem powyżej (/etc/passwd-s3fs).
Korzystanie z pamięci S3
Po zamontowaniu pamięć widoczna jest w systemie jako kolejny zasób:
Filesystem Size Used Avail Use% Mounted on
s3fs 256T 0 256T 0% /lokalny/punkt/montowaniaTak więc możecie z niej korzystać właściwie dowolnie – pamiętajcie tylko, że z racji tego, że jest to pamięć zdalna, dostęp do niej może być trochę wolniejszy (nawet nie tyle sam transfer, co czas dostępu).
Automatyczne pobieranie plików na dysk lokalny
Ja z tego typu zasobów korzystam wprawdzie do różnych celów, to podstawowym celem dla którego instaluje program s3fs na Raspberry Pi jest automatyczne pobieranie plików z kopiami na lokalny dysk podłączony do Raspberry Pi.
Wygląda to tak, że wszystkie serwery wykonują w nocy kopie zapasowe, które są zapisywane w pamięci S3, a nad ranem z tym zasobem łączy się Raspberry Pi i pobiera pliki na lokalny dysk twardy.
W tym celu korzystam z takiego skryptu uruchamianego za pomocą CRONa:
#!/bin/bash
sudo s3fs kontener /lokalny/punkt/montowania -o url="https://e24files.com" -o passwd_file=/etc/passwd-s3fs -o allow_other
sudo rsync --remove-source-files -rtvu --exclude '.fuse_hidden*' /lokalny/punkt/montowania /lokalny/dysk/na/kopie
sudo fusermount -u /lokalny/punkt/montowania exitDziałanie skryptu jest relatywnie proste – najpierw jest montowany kontener o nazwie „kontener” lokalnie (/lokalny/punkt/montowania), a następnie za pomocą polecenia „rsync” pobieramy z niego wszystkie pliki na lokalny dysk (/lokalny/dysk/na/kopie), po czym następuje odmontowanie zasobu S3 z lokalnego systemu plików.




Pasjonat nowych technologii - od sprzętu po oprogramowanie, od serwerów po smartfony i rozwiązania IoT. Potencjalnie kiepski bloger, bo nie robi zdjęć "talerza" zanim zacznie jeść.
Dumny przyjaciel swoich psów :-)
- Odblokowanie dostępu SSH jako użytkownik „root” w Home Assistant OS - 1970-01-01
- Gen AI w Envato, czyli w ramach usługi Envato Elements mamy teraz dostęp do całego wachlarza narzędzi wspieranych przez AI - 1970-01-01
- DJI Mini 5 Pro, czyli mały dron z klasą C0, a spore zamieszanie, bo niby sub250, a jednak waży powyżej 250 gramów - 1970-01-01








Myślę, że wydajniejszym, mniej złożonym i mniej awaryjnym rozwiązaniem jest jednak używanie boto (s3cmd, s4cmd), jeżeli chce się tylko pobrać kilka plików.
Tak – zgadzam się, ale są to właśnie programy do ściśle określonego celu, a ja chciałem przedstawić bardziej uniwersalne zastosowanie (np. jako magazyn na multimedia) stąd s3fs, który ma taką zaletę, że S3 jest widoczny w systemie jako normalny zasób dyskowy, a tym samym bardziej uniwersalny (mój przykład z końcówki wpisu dotyczący pobierania plików to tylko przykład, i wprawdzie ten skrypt montuje zasób tylko na czas swojej pracy, to jednak w systemie pamięć S3 jest wykorzystywana szerzej :-))
Ale może faktycznie warto będzie zaktualizować wpis o s3cmd/s4cmd, choć nie wiem, czy uda mi się to jeszcze dziś…
Cały czas przy próbie kompilacji (make) dostaje komunikat:
//lib/arm-linux-gnueabihf/libpthread.so.0: error adding symbols: DSO missing from command line
collect2: ld returned 1 exit status
Makefile:309: polecenia dla obiektu 's3fs’ nie powiodły się
make[2]: *** [s3fs] Błąd 1
make[2]: Opuszczenie katalogu '/home/[…]/s3fs-fuse/src’
Makefile:321: polecenia dla obiektu 'all-recursive’ nie powiodły się
make[1]: *** [all-recursive] Błąd 1
make[1]: Opuszczenie katalogu '/home/[…]/s3fs-fuse’
Makefile:261: polecenia dla obiektu 'all’ nie powiodły się
make: *** [all] Błąd 2
Nie bardzo wiem jak pomóc, bo przyczyn pewnie może być wiele – poszukaj może informacji o -pthread/-lpthread, może to coś pomoże (z tego co kojarzę, to kiedyś jakieś wątki na ten temat były choćby na oficjalnym forum Raspberry Pi).
Sprawdziłem na szybko na innej Malinie, też z zaktualizowanym Debianem Jessie (system prawie nówka, więc bez jakiś nadzwyczajnych pakietów) i poszło bez problemów. Sprawdziłem na VPSie z Debianem 7, też OK.
Może – stary Windowsowiec ze mnie, i tu często to pomaga – restart systemu, skasowanie „s3fs-fuse” z katalogu domowego i ponowna próba? Może na innym (np. root) użytkowniku?
Cześć,
Ciekawostka że przy instalacji Debiana 8 na stareńkiej stacjonarce (x2) kompilacja poszła bez problemu a na Malince cały czas zonk :(
Pomogło dopiero wyedytowanie pliku ~/s3fs-fuse/src/Makefile i dodanie w sekcji CXXFLAGS opcji -lpthread (CXXFLAGS = -g -O2 -Wall -D_FILE_OFFSET_BITS=64 -lpthread).
Dodatkowo wszystkie czynności poza make install robiłem na koncie zwykłego użytkownika.
No właśnie coś mi się kojarzyło z błędem DSO i „lpthread” jako rozwiązaniem, dlatego w sumie tylko tyle mogłem napisać we wcześniejszym komentarzu, byś może faktycznie gdzieś w tym kierunku poszukał rozwiązania – i fajnie, że się udało.
Ja ostatnią kompilację robiłem na Raspberry Pi model B (512 MB RAM), właściwie czysty Debian 8 Jessie (Raspbian) i poszło bez problemów. Debian 8 na Malinie to czysta instalka, czy aktualizacja z Wheezy? Bo może tu (w aktualizacji) jest rozwiązanie?
No i dzięki za komentarz z informacją, pewnie komuś się jeszcze przyda.
Oj ja już parę latek nic nie kompilowałem pod linuxem, więc trzeba było odświeżyć pamięć :)
Problem był zarówno przy świeżej instalacji jak i przy aktualizacji.
Dzięki za info, oszczędzi mi to instalowania Wheeze i aktualizowania do Jessie by sprawdzić (i ew uzupełnić poradnik) czy gdzieś na tym etapie nie tworzy się problem który opisałeś (zwłaszcza że sobotni poranek – po wizycie na targu i wyjściu z pasami – zacząłem od szukania przyczyny błędu „transport endpoint is not connected” przy montowaniu zasobu za pomocą s3fs).
Ja z Linuxem niby na co dzień teraz, ale tylko dla Pi i VPSów – zresztą taki poważniejszy kontakt z Linuxem (wcześniej niby coś tam, coś tam, ale to było naprawdę podstawy) zacząłem od Raspberry Pi i VPSów, bo tak to jestem wiernym użytkownikiem Windowsa, a w pracy (byłym, bo od kilku lat na swoim) byłem administratorem systemów Windows NT/ActiveDirectory/IIS ;-)